Версия для печати
Большая Дилемма вокруг Больших Данных
6 июня 2013 В течение последних нескольких месяцев скептически настроенные аналитики высказывают все больше критики по отношению к Большим Данным. Тем не менее, их замечания не находят единомышленников, так как все понимают, что Большие Данные – не Идеальные Данные. (Материал опубликован на английском языке)It might be provocative to call into question one of the hottest tech movements in generations, but it’s not really fair. That’s because how companies and people benefit from big data, data science or whatever else they choose to call the movement toward a data-centric world is directly related to what they expect going in. Arguing that big data isn’t all it’s cracked up to be is a strawman, pure and simple — because no one should think it’s magic to begin with.
Correlation versus causation versus “what’s good enough for the job”
One of the biggest complaints — or, in some cases, proposed facts — about big data is that is relies more on correlation than causation in order to find its vaunted insights. To the extent that’s true, it’s a fair criticism. Only I’m not certain how often it’s true for things that really matter.
Honestly, for song or product recommendations, who really cares?
But in areas like medicine, finance and even marketing, people are becoming much more concerned with finding out “why” once they’ve found out “what.” If you’re a police department trying to figure out a strategy for stopping people on the street, for example, even a strong correlation between race and certain crimes probably won’t be enough to justify harassing minorities. Oncologists might benefit from seeing the similarities among cells in a biopsy, but targeting certain markers doesn’t guarantee you can cure someone’s cancer.
Or if you’re a retail store, knowing that Mac users who visit your site tend to buy more-expensive products might make you want to show them more-expensive products. Some deeper digging — perhaps even via direct questions — would show they’re really concerned with craftsmanship. The more you learn beyond what a clustering algorithm can tell you, the better you can connect with customers.
This is why some people call the process of asking interesting questions of data “exploratory analytics.” Data analysts can send out a virtual Christopher Columbus to see what’s doing inside their data. If they find something potentially valuable, they dig in further. Correlations are just a notice that there might be something worth looking at here.

And even in the realm of machine learning — where algorithms are tearing through datasets trying to discover complex patterns humans could never spot — very few people are seriously suggesting we take the machines at their word. In case after case after case, the story is the same: machines do the heavy lifting but humans still play critical roles in training the models by correcting mistakes or adding judgment into an otherwise entirely logical process.
Web data is only part of big data
There’s another idea floating around, too, which is that web-derived data — be it from social media, search queries or some other place — is somehow synonymous with big data. Critics are quick to point out that there are biases in this type of data and that we shouldn’t abolish traditional methods of qualitative, non-digital research in lieu of methods utilizing this fast, easy web data. Of course these critics are right.
But who is really suggesting we do away with traditional forms of research? Social media data shouldn’t usurp traditional customer service or market research data that’s still useful, nor should the Centers for Disease Control start relying on Google Flu Trends at the expense of traditional flu-tracking methodologies. Web and social data are just one more source of data to factor into decisions, albeit a potentially voluminous and high-velocity one.
Even if they’re biased or perhaps even slightly misleading, though, these new data types are still valuable, even for social science research. It is a source of new, large, and arguably unfiltered insights into attitudes and behaviors that were previously difficult to track in the wild. I’m thinking of the researchers who identified new insights into bullying by studying Twitter activity, and of those who have mapped racist tweets across the United States.
The drawbacks should be pretty easy to overcome. Demographic or other biases might be relatively easy to spot when information is also tagged with geodata and perhaps profile information, for example. And assuming the data is mostly indicative of macro trends, there’s definitely value in being able to track it by the day, hour or minute and see trends shaping up in something far closer to real time than traditional research methods would allow.
It’s not all about insights
Which brings me to another point, this one about the idea that big data is all about finding out new things through exploration. Sure, that can be the case if you’re starting to analyze entirely new data sources (like social media data) or using entirely new techniques, and it’s a very compelling reason to get started down the big data path. But sometimes big data is just about automation.
Technologies like Hadoop, for example, aren’t designed to write you better models — they’re designed to process a lot more data a lot faster. If your models still work, Hadoop should help you run them better against a much larger dataset. That might lead to more accurate models and faster answers, but it won’t necessarily lead to some “a ha” moment — like that you’ve been doing business all wrong for all these years.
If you’re a law firm, analyzing e-discovery files faster and more accurately might be reward enough in itself. Or maybe you’re just trying to get a better view of customers or products by putting all your data on them, that you’ve collected over years, into one place. The point is these are valuable objectives even if they don’t involve finding a needle in the haystack.
I think MailChimp is a great example of this. It used big data techniques to discover some interesting things about the characteristics of spam, but the bigger goal was automating the spam-detection process. Those insights don’t directly affect the bottom line, but they did free up resources to help apply data science in others areas that could.
Lower your expectations. Or at least know them
Like anything in IT, big data is almost destined to be a money pit if you go into it without a plan. I’ve heard stories of large-enterprise CIOs deploying Hadoop clusters — sometimes numerous flavors of Hadoop clusters — just because they felt obligated to. I assume there are companies trying desperately to hire data scientists with no real idea what types of problems they’ll be trying to solve. That’s crazy.
In some ways, this type of thinking ties back to the idea that new digital data sources somehow overtake a company’s legacy data in terms importance. Without any actual plan of attack, proposing “We’ll use social media” as a solution to finding out more about consumers is about as useful as proposing “We’ll use Hadoop” as a solution to a question about a big data strategy. Both might very well be parts of any given plan, but they need to be used for what they’re good for.
One major takeaway from my recent interview with MetLife, for example, was how fast the company was able to move on a new data-centric project because it approached it with a plan in place about the types of data and technology it needed. I don’t think it’s surprising, either, to hear the team at Infochimps say that while customers often approach thinking they need Hadoop, it turns out they usually need to begin with something a little less industrial-strength.
So, no, new data types, technologies for processing them and techniques for analyzing them aren’t going to change the world through their mere existence. At the worst, they’re just bigger, shinier and arguably better versions of what we already had. At the best, however — and used appropriately — they really could make a big difference.
Big data will never equal perfect data, but it can definitely point us in the right direction.
Source: gigaom.com
Correlation versus causation versus “what’s good enough for the job”
One of the biggest complaints — or, in some cases, proposed facts — about big data is that is relies more on correlation than causation in order to find its vaunted insights. To the extent that’s true, it’s a fair criticism. Only I’m not certain how often it’s true for things that really matter.
Honestly, for song or product recommendations, who really cares?
But in areas like medicine, finance and even marketing, people are becoming much more concerned with finding out “why” once they’ve found out “what.” If you’re a police department trying to figure out a strategy for stopping people on the street, for example, even a strong correlation between race and certain crimes probably won’t be enough to justify harassing minorities. Oncologists might benefit from seeing the similarities among cells in a biopsy, but targeting certain markers doesn’t guarantee you can cure someone’s cancer.
Or if you’re a retail store, knowing that Mac users who visit your site tend to buy more-expensive products might make you want to show them more-expensive products. Some deeper digging — perhaps even via direct questions — would show they’re really concerned with craftsmanship. The more you learn beyond what a clustering algorithm can tell you, the better you can connect with customers.
This is why some people call the process of asking interesting questions of data “exploratory analytics.” Data analysts can send out a virtual Christopher Columbus to see what’s doing inside their data. If they find something potentially valuable, they dig in further. Correlations are just a notice that there might be something worth looking at here.
Clusters show where oncologists should start investigating. Source: Columbia University
And even in the realm of machine learning — where algorithms are tearing through datasets trying to discover complex patterns humans could never spot — very few people are seriously suggesting we take the machines at their word. In case after case after case, the story is the same: machines do the heavy lifting but humans still play critical roles in training the models by correcting mistakes or adding judgment into an otherwise entirely logical process.
Web data is only part of big data
There’s another idea floating around, too, which is that web-derived data — be it from social media, search queries or some other place — is somehow synonymous with big data. Critics are quick to point out that there are biases in this type of data and that we shouldn’t abolish traditional methods of qualitative, non-digital research in lieu of methods utilizing this fast, easy web data. Of course these critics are right.
But who is really suggesting we do away with traditional forms of research? Social media data shouldn’t usurp traditional customer service or market research data that’s still useful, nor should the Centers for Disease Control start relying on Google Flu Trends at the expense of traditional flu-tracking methodologies. Web and social data are just one more source of data to factor into decisions, albeit a potentially voluminous and high-velocity one.
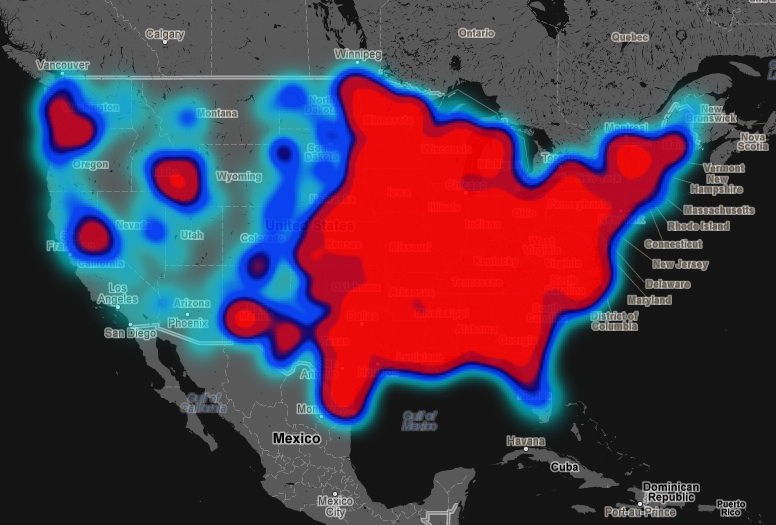
Even if they’re biased or perhaps even slightly misleading, though, these new data types are still valuable, even for social science research. It is a source of new, large, and arguably unfiltered insights into attitudes and behaviors that were previously difficult to track in the wild. I’m thinking of the researchers who identified new insights into bullying by studying Twitter activity, and of those who have mapped racist tweets across the United States.
Floating Sheep’s Hate Map
The drawbacks should be pretty easy to overcome. Demographic or other biases might be relatively easy to spot when information is also tagged with geodata and perhaps profile information, for example. And assuming the data is mostly indicative of macro trends, there’s definitely value in being able to track it by the day, hour or minute and see trends shaping up in something far closer to real time than traditional research methods would allow.
It’s not all about insights
Which brings me to another point, this one about the idea that big data is all about finding out new things through exploration. Sure, that can be the case if you’re starting to analyze entirely new data sources (like social media data) or using entirely new techniques, and it’s a very compelling reason to get started down the big data path. But sometimes big data is just about automation.
Technologies like Hadoop, for example, aren’t designed to write you better models — they’re designed to process a lot more data a lot faster. If your models still work, Hadoop should help you run them better against a much larger dataset. That might lead to more accurate models and faster answers, but it won’t necessarily lead to some “a ha” moment — like that you’ve been doing business all wrong for all these years.
If you’re a law firm, analyzing e-discovery files faster and more accurately might be reward enough in itself. Or maybe you’re just trying to get a better view of customers or products by putting all your data on them, that you’ve collected over years, into one place. The point is these are valuable objectives even if they don’t involve finding a needle in the haystack.
I think MailChimp is a great example of this. It used big data techniques to discover some interesting things about the characteristics of spam, but the bigger goal was automating the spam-detection process. Those insights don’t directly affect the bottom line, but they did free up resources to help apply data science in others areas that could.
Lower your expectations. Or at least know them
Like anything in IT, big data is almost destined to be a money pit if you go into it without a plan. I’ve heard stories of large-enterprise CIOs deploying Hadoop clusters — sometimes numerous flavors of Hadoop clusters — just because they felt obligated to. I assume there are companies trying desperately to hire data scientists with no real idea what types of problems they’ll be trying to solve. That’s crazy.
In some ways, this type of thinking ties back to the idea that new digital data sources somehow overtake a company’s legacy data in terms importance. Without any actual plan of attack, proposing “We’ll use social media” as a solution to finding out more about consumers is about as useful as proposing “We’ll use Hadoop” as a solution to a question about a big data strategy. Both might very well be parts of any given plan, but they need to be used for what they’re good for.
One major takeaway from my recent interview with MetLife, for example, was how fast the company was able to move on a new data-centric project because it approached it with a plan in place about the types of data and technology it needed. I don’t think it’s surprising, either, to hear the team at Infochimps say that while customers often approach thinking they need Hadoop, it turns out they usually need to begin with something a little less industrial-strength.
So, no, new data types, technologies for processing them and techniques for analyzing them aren’t going to change the world through their mere existence. At the worst, they’re just bigger, shinier and arguably better versions of what we already had. At the best, however — and used appropriately — they really could make a big difference.
Big data will never equal perfect data, but it can definitely point us in the right direction.
Source: gigaom.com

